Robots.txt Ultimate 2019 Guide

Robots.txt (also called the robots exclusion protocol or standard) was first proposed by Martijn Koster, when working for Nexor in February 1994. It is a file that sits in your websites root directory and is a subject that has caused much confusion over the years and still does even among SEOs! So with this article I will aim to simplify it a bit for you and guide you in its best uses in 2019.
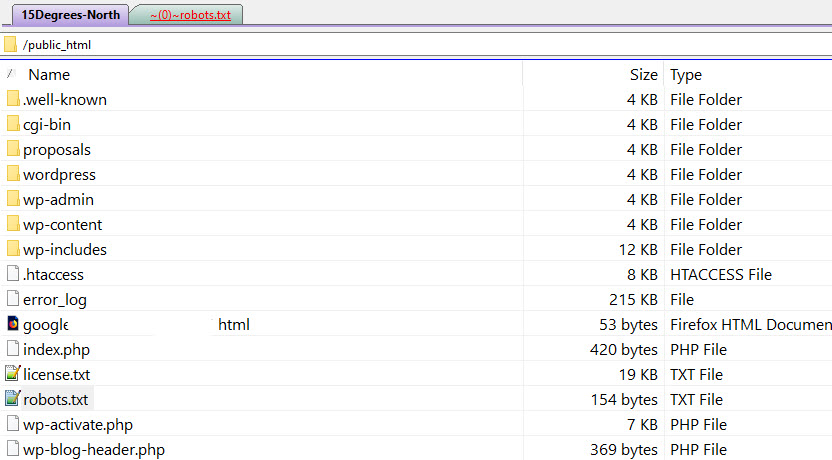
This is what the Robots.txt file looks like on my server:

As you can see it does not look much does it. Most people that I know don’t know about it and even fewer actually know what to do with it. You do need a certain amount of coding savvy to be able to get the best out of this little file and also what NOT to use it for.
Why the robots.txt file is important
So in a nutshell this little file tells search engine crawlers (bots, spiders) what they can and also what they can’t crawl on your website. Here is a list of the main spiders for you. There are many many more and a lot of bad ones too looking for email addresses and such like.
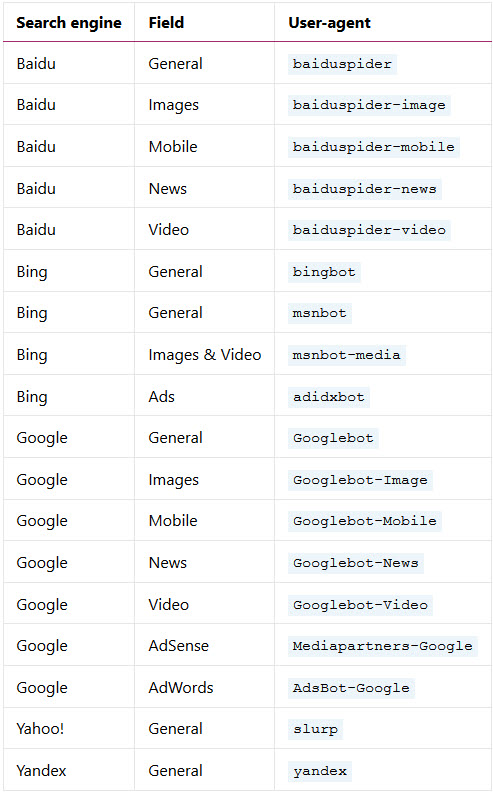
Generally speaking most websites don’t actually need a robots.txt file to be present.
The reason for this is that Google and all the other spiders and bots out there can usually find, catalogue and index all of the important pages on your site without it. They are quite clever these little bots.
They will also NOT index pages that are classed as not important and they also wont index duplicate versions of other pages on your site either.
Now is saying that, there are 3 main and fundamental reasons why you do want to use a robots.txt file on your site.
- To Block pages that are not public: You may have a staging site on your main site (we do) which is a copy of your main site for development and testing purposes. Of course you don’t want this seen or indexed because you don’t want random people to see them. So you would simply block them in your robots file.
- To Maximize Your Crawl Budget: You may have a huge ecom site with thousands of pages and you’re having a rough time of it getting some of your pages indexed and ranking at all. This may be because you have a crawl budget problem. if this is the case then you can block all the unimportant pages on your site with robots.txt and thus Googlebot and others can then spend more of your crawl budget on the pages that actually matter to you.
- You may want to Prevent the Indexing of Resources: You can use meta directives (my preferred method actually) for this and it works just as well as Robots.txt for preventing and blocking pages from getting indexed. However it should be noted that meta directives don’t work that well for multimedia resources, like PDFs and images. This is where you would use robots.txt instead.
Robots.txt tells search engine spiders and bots where they can and where they cannot go on your website. It should be noted that a lot of bots ignore it altogether regardless of what you put in it.
As with all things there is a caveat here with relation to point two above. What do we class as unimportant pages? Here are a few examples for you.
Client profile pages that are never filled in or used could be classed as low value
Staging sites or hidden areas of your site that you don’t want to be seen or crawled
Multiple cPanel login language pages
PDFs and other content that you don’t need to appear in the index
Images and or image directory’s
So does blocking all this stuff magically make you rank better? NO is the answer as Google says here:
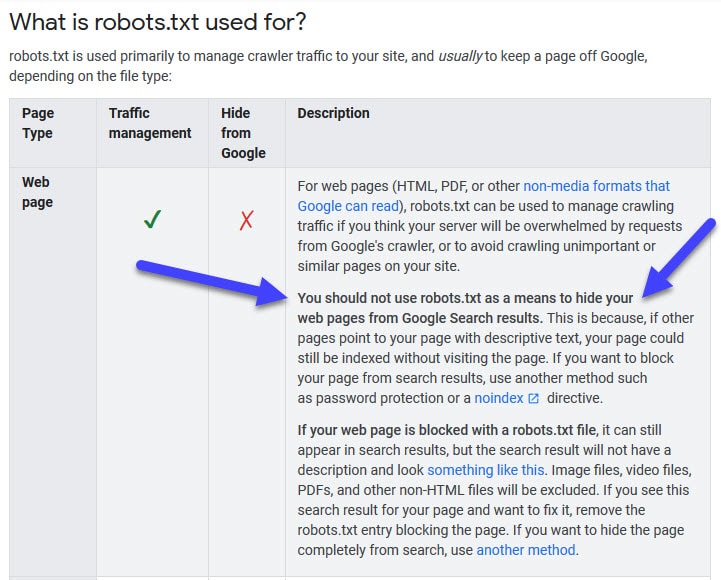
What it does is frees up crawl budget and bandwidth if you have crawl budget or bandwidth issues. It frees up budget and allows you to get more pages into the index. Blocking of low value web pages or products does not in of itself magically make your other (what you consider) high value products or pages rank higher. Ah if only SEO was so easy eh!
This is what Google considers to be Low value:

Here is how Google explains crawl budget
Firstly is Crawl Rate Limit:

So as you can see it is imperative to fix all of the issues that are thrown up in your technical site audit because all of them play a part in your allotted crawl budget.
Next is Crawl Demand:

Some notes from Google themselves.

Ah but is crawling a ranking factor?

NO then! Increasing your crawl budget, hiding pages within robots.txt does NOT increase your rankings according to Google. As I said above all that hiding pages and areas of your site does is allow you to get more of your valuable pages into the index. That’s it. Hiding what you consider to be low value pages in the hopes that Google will then magically rank your other pages higher does not work.
A lot of SEO’s and some site owners get mighty confused over this it should be said.
Creating a Robots.txt File
Ok so we have discussed what robots.txt is now lets look at some examples and implementations of it. So firstly if you have not got one you can create it in windows. It’s just a text file after all. So right click on your desktop and click create new text file. Call it robots.txt like this: Lower case please.

Now open it using your text editor. I use NotePad++ for all text file editing if you’re wondering why mine is green 🙂 Add these three lines into it like below:
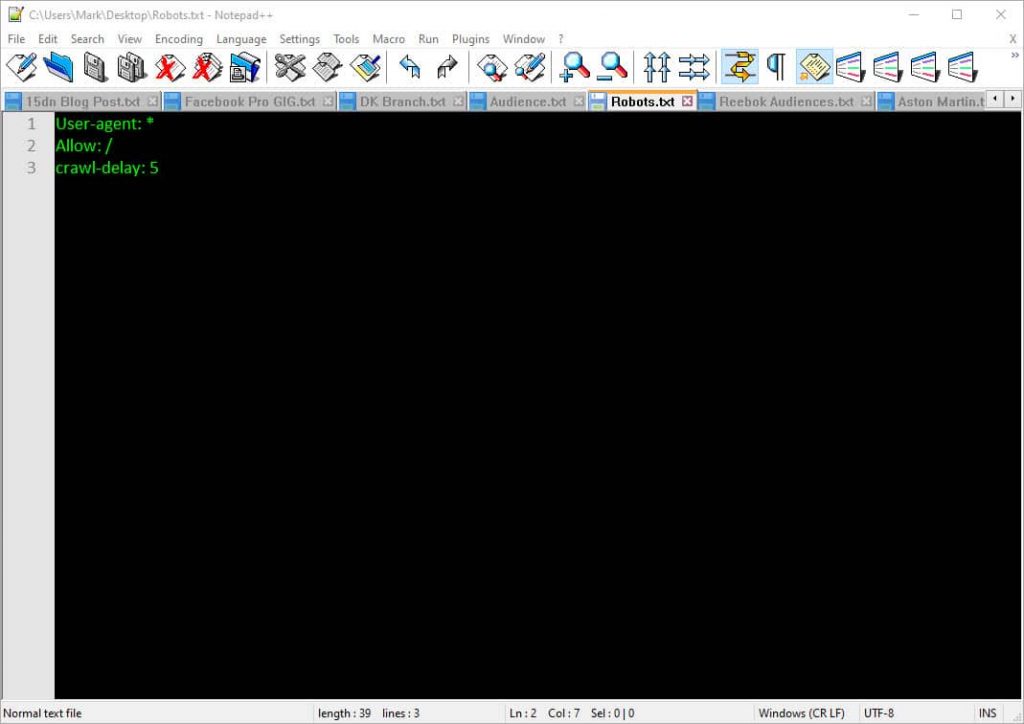
User-agent: * = Allows all robots and spiders to access your site
Allow: / = You are allowing them to access and crawl your whole site
Crawl- delay: 5 =
Yahoo!, Bing and Yandex are sometimes very crawl-hungry. However they all respond to the “crawl delay” directive, which does serve to slow them down. Now while these search engines do have slightly different ways of reading this command, the end result is the same.
A line like the one below instructs spiders like Yahoo and Bing to wait that many seconds after a crawl action. Yandex on the other hand would only access your site once every 5 seconds.
crawl-delay: 10
Take care when using the “crawl-delay” directive. Setting a crawl delay of 10 seconds for example allows these search engines to access 8,640 pages a day. For a small site that’s plenty, but on large ecom sites it isn’t very many. If you get next to no traffic from these search engines, it’s a good way to save some server bandwidth.
You can check which bots are visiting your site in your server logs and also see how much bandwidth they consume when they visit.
It should be noted here that Google does not support crawl-delay command. You used to be able to set crawl delay for Google in your Google search console but it appears they have removed that now in the new console view. Either way Google ignores it anyway.
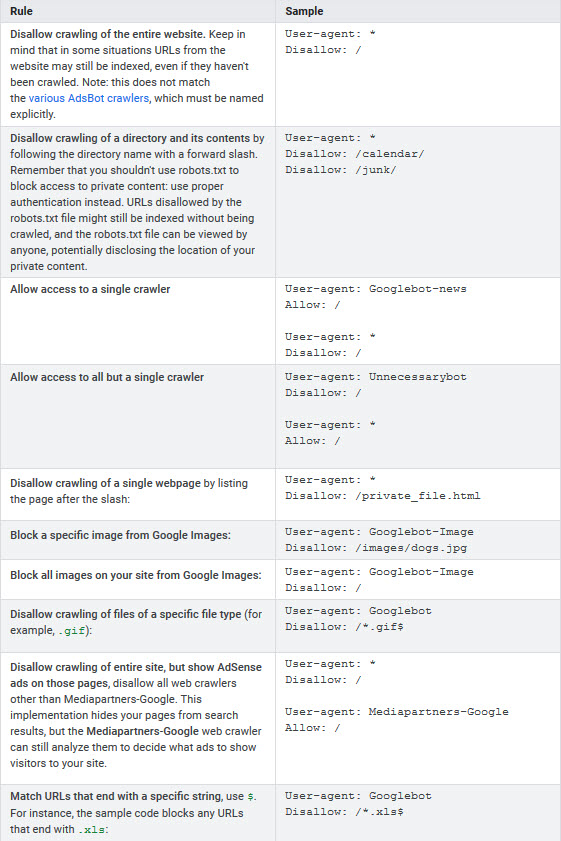
Example Robots Text Commands
Here is a list of examples of how you can craft your robots.txt file to suit your site.
So now your happy with your little robots file you need to upload it to your root or home directory like so
http://www.example.com/robots.txt.
It cannot be placed in a subdirectory ( for example, at http://example.com/pages/robots.txt).
As you can see mine is in /public_html directory
Checking Robots.txt For Errors
Once you have created your file and also uploaded it to your home directory on your server you can check it with Googles own Robot.txt tool.
I’m not sure how long this tool will be available as it is in the old version of Search Console so might be removed. But for the time being it does work.
In Summary
- Robots.txt file is useful for telling crawlers where they can and where they cannot go on your web server
- Its correct application will help to free up server bandwidth
- Its correct application will help to free up crawl budget on larger sites and help you to get more pages indexed and ultimately ranked
- It does NOT help you to rank existing pages at all
- Blocking of individual pages is better done using the meta directives tag on the page itself and NOT in the robots.txt file
- It is not a ranking factor and nor is crawl budget


0 Comments